1 pavyzdys: DataFrame rūšiavimas naudojant Order() metodą R
Funkcija order() R yra naudojama DataFrames rūšiuoti pagal vieną ar kelis stulpelius. Užsakymo funkcija gauna surūšiuotų eilučių indeksus, kad pertvarkytų DataFrame eilutes.
emp = duomenis. rėmelis ( vardai = c ( 'Andy' , 'Ženklas' , 'Bonnie' , 'Karolina' , 'Jonas' ) ,amžiaus = c ( dvidešimt vienas , 23 , 29 , 25 , 32 ) ,
atlyginimas = c ( 2000 m , 1000 , 1500 , 3000 , 2500 ) )
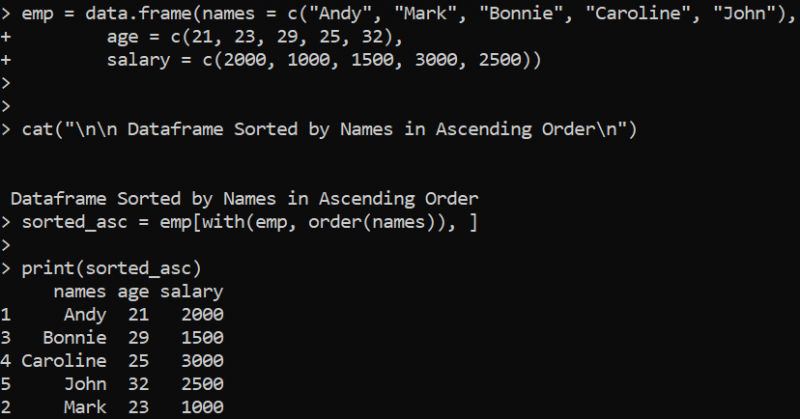
katė ( “ \n \n Duomenų rėmeliai surūšiuoti pagal pavadinimus didėjančia tvarka \n “ )
surūšiuotas_asc = emp [ su ( emp , įsakymas ( vardai ) ) , ]
spausdinti ( surūšiuotas_asc )
Čia mes apibrėžiame 'emp' DataFrame su trimis stulpeliais, kuriuose yra skirtingos reikšmės. Funkcija cat() naudojama spausdinti teiginį, nurodantį, kad 'emp' DataFrame stulpelyje 'pavadinimai' didėjimo tvarka bus rūšiuojamas. Tam naudojame R funkciją order(), kuri grąžina reikšmių indekso pozicijas vektoriuje, kuris surūšiuotas didėjančia tvarka. Šiuo atveju funkcija with() nurodo, kad stulpelis „pavadinimai“ turi būti rūšiuojamas. Surūšiuotas duomenų rėmelis yra saugomas kintamajame „sorted_asc“, kuris perduodamas kaip argumentas funkcijoje print(), kad būtų spausdinami surūšiuoti rezultatai.
Taigi duomenų rėmelio rezultatai, surūšiuoti pagal stulpelį „pavadinimai“ didėjančia tvarka, rodomi toliau. Norėdami gauti rūšiavimo operaciją mažėjančia tvarka, galime tiesiog nurodyti neigiamą ženklą su stulpelio pavadinimu ankstesnėje order() funkcijoje:
2 pavyzdys: DataFrame rūšiavimas naudojant Order() metodo parametrus R
Be to, funkcija order() naudoja mažėjančius argumentus, kad surūšiuotų DataFrame. Šiame pavyzdyje nurodome order() funkciją su argumentu, kad būtų galima rūšiuoti didėjančia arba mažėjančia tvarka:
df = duomenis. rėmelis (
id = c ( 1 , 3 , 4 , 5 , 2 ) ,
kursą = c ( 'Python' , 'Java' , 'C++' , 'MongoDB' , 'R' ) )
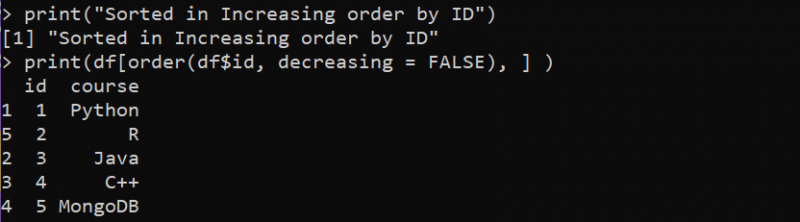
spausdinti ( „Rūšiuojama mažėjančia tvarka pagal ID“ )
spausdinti ( df [ įsakymas ( df$id , mažėja = TIESA ) , ] )
Čia pirmiausia deklaruojame „df“ kintamąjį, kur data.frame() funkcija yra apibrėžta trimis skirtingais stulpeliais. Tada naudojame funkciją print(), kur išspausdiname pranešimą, nurodantį, kad DataFrame bus rūšiuojamas mažėjančia tvarka pagal stulpelį „id“. Po to vėl įdiegiame funkciją print(), kad atliktume rūšiavimo operaciją ir išspausdintume tuos rezultatus. Funkcijoje print () mes vadiname funkciją „order“, kad surūšiuotume „df“ duomenų rėmelį pagal „kurso“ stulpelį. Argumentas „mažėjantis“ nustatytas į TRUE, kad būtų galima rūšiuoti mažėjimo tvarka.
Toliau pateiktoje iliustracijoje „DataFrame“ stulpelis „id“ yra išdėstytas mažėjančia tvarka:

Tačiau norėdami gauti rūšiavimo rezultatus didėjančia tvarka, turime nustatyti mažėjantį order() funkcijos argumentą FALSE, kaip parodyta toliau:
spausdinti ( „Rūšiuojama didėjančia tvarka pagal ID“ )spausdinti ( df [ įsakymas ( df$id , mažėja = NETEISINGA ) , ] )
Ten gauname DataFrame rūšiavimo operacijos išvestį stulpelyje „id“ didėjančia tvarka.
3 pavyzdys: DataFrame rūšiavimas naudojant Arrange() metodą R
Be to, mes taip pat galime naudoti arrange() metodą, norėdami rūšiuoti DataFrame pagal stulpelius. Taip pat galime rūšiuoti didėjimo arba mažėjimo tvarka. Šis pateiktas R kodas naudoja funkciją arrange():
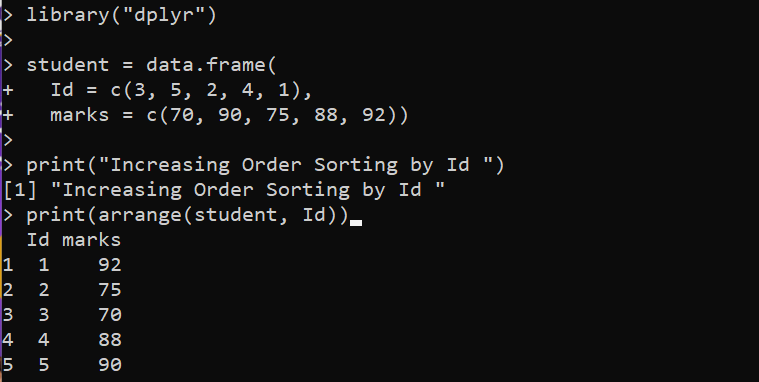
biblioteka ( 'dplyr' )studentas = duomenis. rėmelis (
Id = c ( 3 , 5 , 2 , 4 , 1 ) ,
ženklų = c ( 70 , 90 , 75 , 88 , 92 ) )
spausdinti ( „Užsakymų rūšiavimo pagal ID didinimas“ )
spausdinti ( sutvarkyti ( studentas , Id ) )
Čia įkeliame R paketą „dplyr“, kad pasiektume „arrange()“ metodą rūšiavimui. Tada turime funkciją data.frame(), kurią sudaro du stulpeliai ir DataFrame nustatomas į kintamąjį „studentas“. Tada mes įdiegiame funkciją arrange () iš „dplyr“ paketo funkcijoje print (), kad surūšiuotume nurodytą duomenų rėmelį. Funkcija „arrange()“ kaip pirmąjį argumentą pasirenka „studento“ duomenų rėmelį, po kurio nurodomas stulpelių „Id“, pagal kuriuos reikia rūšiuoti. Pabaigoje esanti funkcija print() atspausdina surūšiuotą duomenų rėmelį į konsolę.
Mes matome, kur stulpelis „Id“ yra surūšiuotas seka šioje išvestyje:
4 pavyzdys: DataFrame rūšiavimas pagal datą R
R „DataFrame“ taip pat gali būti rūšiuojamas pagal datos reikšmes. Norėdami tai padaryti, surūšiuota funkcija turi būti nurodyta su as.date() funkcija, kad būtų formatuojamos datos.
renginio data = duomenis. rėmelis ( įvykis = c ( „2023-03-04“ , „2023-02-02“ ,„2023-10-01“ , „2023-03-29“ ) ,
mokesčiai = c ( 3100 , 2200 , 1000 , 2900 ) )
renginio data [ įsakymas ( kaip . Data ( įvykio_data$įvykis , formatu = „%d/%m/%Y“ ) ) , ]
Čia mes turime „event_date“ duomenų rėmelį, kuriame yra „įvykio“ stulpelis su datos eilutėmis „mėnuo/diena/metai“ formatu. Turime rūšiuoti šias datos eilutes didėjančia tvarka. Mes naudojame funkciją order(), kuri surūšiuoja DataFrame pagal stulpelį „įvykis“ didėjančia tvarka. Tai pasiekiame konvertuodami datos eilutes stulpelyje „įvykis“ į tikrąsias datas naudodami funkciją „as.Date“ ir nurodydami datos eilučių formatą naudodami parametrą „format“.
Taigi mes pateikiame duomenis, kurie yra surūšiuoti pagal „įvykio“ datos stulpelį didėjančia tvarka.

5 pavyzdys: DataFrame rūšiavimas naudojant Setorder() metodą R
Panašiai setorder () taip pat yra dar vienas būdas rūšiuoti DataFrame. Jis rūšiuoja DataFrame, atsižvelgdamas į argumentą, kaip ir arrange() metodas. Metodo setorder() R kodas pateikiamas taip:
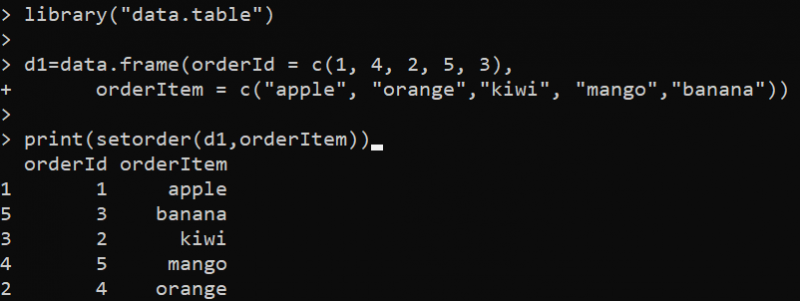
biblioteka ( 'duomenys.lentelė' )d1 = duomenis. rėmelis ( orderId = c ( 1 , 4 , 2 , 5 , 3 ) ,
užsakyti prekę = c ( 'obuolys' , 'oranžinė' , 'kivi' , 'mangas' , 'bananas' ) )
spausdinti ( nustatyti tvarką ( d1 , užsakyti prekę ) )
Čia pirmiausia nustatome data.table biblioteką, nes setorder() yra šio paketo funkcija. Tada mes naudojame funkciją data.frame(), kad sukurtume DataFrame. DataFrame nurodomas tik dviem stulpeliais, kuriuos naudojame rūšiavimui. Po to mes nustatome funkciją setorder () funkcijoje print (). Funkcija setorder() pasirenka „d1“ DataFrame kaip pirmąjį parametrą, o stulpelį „orderId“ – kaip antrą parametrą, pagal kurį rūšiuojamas duomenų rėmelis. Funkcija „setorder“ perskirsto duomenų lentelės eilutes didėjančia tvarka pagal „orderId“ stulpelio reikšmes.
Surūšiuotas DataFrame yra šios R konsolės išvestis:
6 pavyzdys: „DataFrame“ rūšiavimas naudojant „Rw.Names()“ metodą
Metodas row.names() taip pat yra būdas rūšiuoti DataFrame R. row.names() rūšiuoja DataFrames pagal nurodytą eilutę.
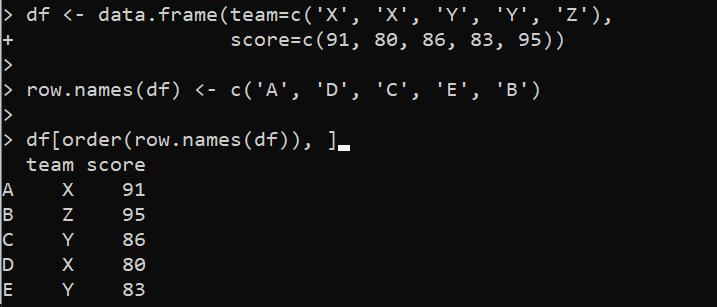
df < - duomenys. rėmelis ( komanda = c ( 'X' , 'X' , 'IR' , 'IR' , 'SU' ) ,balas = c ( 91 , 80 , 86 , 83 , 95 ) )
eilė. vardai ( df ) < - c ( 'A' , 'D' , 'C' , 'IR' , 'B' )
df [ įsakymas ( eilė. vardai ( df ) ) , ]
Čia funkcija data.frame() yra nustatyta kintamajame „df“, kur stulpeliai nurodomi su reikšmėmis. Tada DataFrame eilučių pavadinimai nurodomi naudojant row.names() funkciją. Po to iškviečiame funkciją order(), kad surūšiuotume DataFrame pagal eilučių pavadinimus. Funkcija order() grąžina surūšiuotų eilučių indeksus, kurie naudojami pertvarkant DataFrame eilutes.
Išvestis rodo surūšiuotą DataFrame pagal eilutes abėcėlės tvarka:
Išvada
Mes matėme skirtingas funkcijas, skirtas rūšiuoti duomenų rėmelius R. Kiekvienas metodas turi pranašumą ir reikalauja rūšiavimo operacijos. Gali būti daugiau metodų ar būdų rūšiuoti DataFrame R kalba, tačiau order(), arrange() ir setorder() metodai yra patys svarbiausi ir lengviausia naudoti rūšiuojant.