Pandos užpildo NaN vertes
Jei duomenų rėmelio stulpelyje yra NaN arba None reikšmės, galite naudoti „fillna()“ arba „replace()“ funkcijas, kad užpildytumėte jas nuliu (0).
užpildyti ()
NA / NaN reikšmės užpildomos pateiktu metodu, naudojant funkciją „fillna ()“. Jis gali būti naudojamas atsižvelgiant į šią sintaksę:
Jei norite užpildyti NaN reikšmes vienam stulpeliui, sintaksė yra tokia:

Kai reikia užpildyti viso DataFrame NaN reikšmes, sintaksė yra tokia:

Pakeisti ()
Norint pakeisti vieną NaN reikšmių stulpelį, pateikiama tokia sintaksė:

Tuo tarpu norėdami pakeisti visas „DataFrame“ NaN reikšmes, turime naudoti šią minėtą sintaksę:

Šiame rašte mes dabar ištirsime ir išmoksime praktiškai įgyvendinti abu šiuos metodus, kad užpildytume NaN reikšmes mūsų Pandas DataFrame.
1 pavyzdys: užpildykite NaN reikšmes naudodami Pandas „Fillna()“ metodą
Šioje iliustracijoje pavaizduotas Pandas funkcijos „DataFrame.fillna()“ taikymas, norint užpildyti NaN reikšmes duotame DataFrame su 0. Galite užpildyti trūkstamas reikšmes viename stulpelyje arba galite užpildyti jas visam DataFrame. Čia pamatysime abu šiuos metodus.
Norėdami įgyvendinti šias strategijas, turime gauti tinkamą platformą programos vykdymui. Taigi, mes nusprendėme naudoti „Spyder“ įrankį. „Python“ kodą pradėjome importuodami į programą „pandos“ įrankių rinkinį, nes turime naudoti „Pandas“ funkciją, kad sukurtume „DataFrame“ ir užpildytų trūkstamas reikšmes tame „DataFrame“. „Pd“ visoje programoje naudojamas kaip „pandos“ slapyvardis.
Dabar turime prieigą prie Pandos funkcijų. Pirmiausia naudojame jos funkciją „pd.DataFrame()“, kad sukurtume savo DataFrame. Mes panaudojome šį metodą ir inicijavome jį trimis stulpeliais. Šių stulpelių pavadinimai yra „M1“, „M2“ ir „M3“. Stulpelio „M1“ reikšmės yra „1“, „Nėra“, „5“, „9“ ir „3“. „M2“ įrašai yra „Nėra“, „3“, „8“, „4“ ir „6“. Nors „M3“ saugo duomenis kaip „1“, „2“, „3“, „5“ ir „Nėra“. Mums reikia „DataFrame“ objekto, kuriame galėtume saugoti šį „DataFrame“, kai iškviečiamas „pd.DataFrame()“ metodas. Sukūrėme „trūkstamą“ DataFrame objektą ir priskyrėme jį pagal rezultatą, kurį gavome iš funkcijos „pd.DataFrame()“. Tada naudojome Python „print ()“ metodą, kad rodytume „DataFrame“ „Python“ konsolėje.
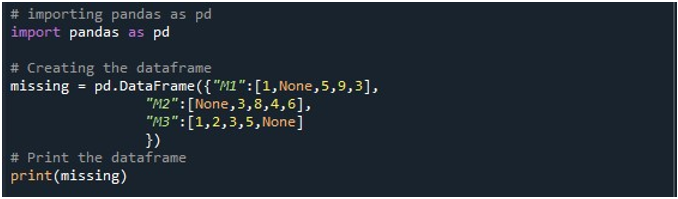
Kai paleidžiame šią kodo dalį, terminale galima peržiūrėti trijų stulpelių duomenų rėmelį. Čia galime pastebėti, kad visuose trijuose stulpeliuose yra nulinės reikšmės.
Sukūrėme duomenų rėmelį su kai kuriomis nulinėmis reikšmėmis, kad pritaikytume Pandas „fillna()“ funkciją ir užpildytų trūkstamas reikšmes 0. Sužinokime, kaip tai padaryti.
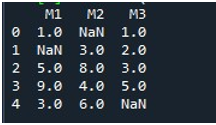
Parodę DataFrame, mes iškvietėme Pandas „fillna()“ funkciją. Čia mes išmoksime užpildyti trūkstamas reikšmes viename stulpelyje. To sintaksė jau paminėta mokymo programos pradžioje. Pateikėme „DataFrame“ pavadinimą ir nurodėme konkretaus stulpelio pavadinimą naudodami funkciją „.fillna()“. Tarp šio metodo skliaustų pateikėme reikšmę, kuri bus dedama į nulines vietas. „DataFrame“ pavadinimo „trūksta“, o stulpelis, kurį pasirinkome čia, yra „M2“. Tarp „fillna()“ skliaustų pateikta reikšmė yra „0“. Galiausiai, norėdami peržiūrėti atnaujintą DataFrame, iškvietėme funkciją „print ()“.

Čia galite pamatyti, kad „DataFrame“ stulpelyje „M2“ dabar nėra trūkstamų reikšmių, nes NaN reikšmė užpildyta 0.
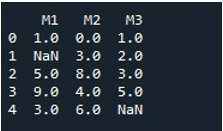
Norėdami užpildyti viso „DataFrame“ NaN reikšmes tuo pačiu metodu, pavadinome „fillna ()“. Tai gana paprasta. Pateikėme DataFrame pavadinimą su funkcija „fillna ()“ ir skliausteliuose priskyrėme funkcijos reikšmę „0“. Galiausiai funkcija „print ()“ parodė mums užpildytą „DataFrame“.

Taip gauname „DataFrame“ be NaN reikšmių, nes visos reikšmės dabar vėl užpildomos 0.
2 pavyzdys: Užpildykite NaN reikšmes naudodami Pandas „Replace()“ metodą
Šioje straipsnio dalyje parodytas kitas būdas užpildyti NaN reikšmes DataFrame. Norėdami užpildyti reikšmes viename stulpelyje ir visame duomenų rėmelyje, naudosime Pandas funkciją „replace()“.
Pradedame rašyti kodą „Spyder“ įrankyje. Pirmiausia importavome reikiamas bibliotekas. Čia įkėlėme Pandas biblioteką, kad Python programa galėtų naudoti Pandas metodus. Antroji biblioteka, kurią įkėlėme, yra „NumPy“ ir pavadinama „np“. NumPy apdoroja trūkstamus duomenis naudodamas „replace()“ metodą.
Tada mes sukūrėme duomenų rėmelį su trimis stulpeliais – „sraigtas“, „vinis“ ir „gręžtuvas“. Vertės kiekviename stulpelyje pateikiamos atitinkamai. Stulpelyje „sraigtas“ yra „112“, „234“, „Nėra“ ir „650“ reikšmės. Stulpelyje „Vinis“ yra „123“, „145“, „Nėra“ ir „711“. Galiausiai stulpelyje „gręžimas“ yra „312“, „Nėra“, „500“ ir „Nėra“ reikšmės. „DataFrame“ saugomas „Tool“ DataFrame objekte ir rodomas naudojant „print()“ metodą.
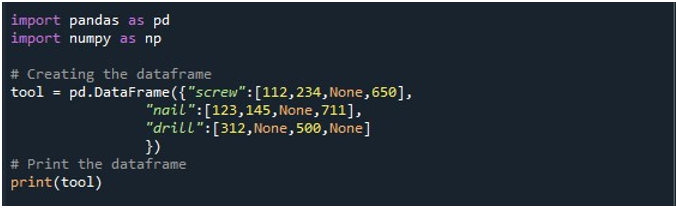
DataFrame su keturiomis NaN reikšmėmis įraše galima pamatyti šiame išvesties vaizde:
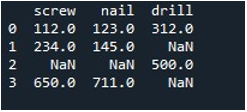
Dabar mes naudojame Pandas „replace()“ metodą, kad užpildytume nulines reikšmes viename „DataFrame“ stulpelyje. Norėdami atlikti užduotį, mes panaudojome funkciją „pakeisti ()“. Pateikėme DataFrame pavadinimą „įrankis“ ir stulpelį „sraigtas“ naudodami „.replace()“ metodą. Tarp skliaustų mes nustatome reikšmę „0“ „np.nan“ įrašams DataFrame. Išvesties rodymui naudojamas metodas „print()“.

Gautas DataFrame rodo mums pirmąjį stulpelį, kuriame NaN įrašai yra pakeisti 0 stulpelyje „sraigtas“.
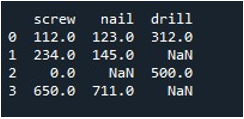
Dabar išmoksime užpildyti reikšmes visame „DataFrame“. Pavadinome metodą „replace()“ su DataFrame pavadinimu ir pateikėme reikšmę, kurią norime pakeisti np.nan įrašais. Galiausiai išspausdinome atnaujintą DataFrame su funkcija „print ()“.

Taip gaunamas duomenų rėmelis be trūkstamų įrašų.
Išvada
Trūkstamų „DataFrame“ įrašų tvarkymas yra esminis ir būtinas reikalavimas siekiant sumažinti sudėtingumą ir nepalankiai tvarkyti duomenis duomenų analizės procese. „Pandas“ siūlo keletą būdų, kaip išspręsti šią problemą. Šiame vadove pateikėme dvi patogias strategijas. Mes pritaikėme abu metodus naudodami „Spyder“ įrankį, kad vykdytume pavyzdinius kodus, kad viskas būtų jums suprantama ir lengviau. Įgiję žinių apie šias funkcijas, paaštrėsite savo Pandos įgūdžius.