Sintaksė
df [ ( cond_1 ) & ( cond_2 ) ]01 pavyzdys
Šiuos kodus atliekame „Spyder“ programėlėje ir naudosime „AND“ operatorių mūsų sąlygomis „pandos“ čia. Kai darome pandų kodus, pirmiausia turime importuoti „pandas kaip pd“ ir gausime jo metodą į savo kodą įtraukę tik „pd“. Tada sugeneruojame žodyną pavadinimu „Cond“ ir čia įterpiami duomenys yra „A1“, „A2“ ir „A3“ yra stulpelių pavadinimai, o „1, 2 ir 3“ pridedame „ A1“, „A2“ yra „2, 6 ir 4“, o paskutiniame „A3“ yra „3, 4 ir 5“.
Tada mes pradedame kurti šio žodyno DataFrame, naudodami čia esantį „pd.DataFrame“. Tai grąžins aukščiau pateiktų žodyno duomenų DataFrame. Mes taip pat pateikiame jį čia pateikdami „spausdinti ()“, o po to taikome kai kurias sąlygas ir šioje sąlygoje naudojame „&“ operatorių. Pirmoji sąlyga yra ta, kad „A1 >= 1“, tada įdedame „&“ operatorių ir įdedame kitą sąlygą, kuri yra „A2 < 5“. Kai tai vykdysime, jis grąžins rezultatą, jei „A1 >=1“ ir „A2 < 5“. Jei čia tenkinamos abi sąlygos, bus rodomas rezultatas, o jei kuri nors iš jų čia netenkinama, duomenų nerodys.
Jis patikrina „DataFrame“ stulpelius „A1“ ir „A2“ ir grąžina rezultatą. Rezultatas rodomas ekrane, nes naudojame teiginį „spausdinti ()“.
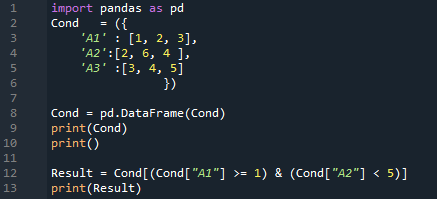
Rezultatas yra čia. Rodo visus duomenis, kuriuos įdėjome į „DataFrame“, tada patikrina abi sąlygas. Jis grąžina tas eilutes, kuriose „A1 >=1“ ir „A2 < 5“. Šiame išvestyje gauname dvi eilutes, nes abi sąlygos tenkinamos dviejose eilutėse.
02 pavyzdys
Šiame pavyzdyje mes tiesiogiai sukuriame DataFrame importavę „pandas kaip pd“. Čia sukuriamas „Team“ duomenų rėmelis su keturiais stulpeliais. Pirmasis stulpelis yra stulpelis „komandos“, į kurį įtraukiame „A, A, B, B, B, B, C, C“. Tada stulpelis šalia „komandų“ yra „balas“, kuriame įterpiame „25, 12, 15, 14, 19, 23, 25 ir 29“. Po to stulpelis, kurį turime, yra „Išeina“, taip pat į jį įtraukiame duomenis kaip „5, 7, 7, 9, 12, 9, 9 ir 4“. Paskutinis mūsų stulpelis yra „atkovotų kamuolių“ stulpelis, kuriame taip pat yra keletas skaitinių duomenų, ty „11, 8, 10, 6, 6, 5, 9 ir 12“.
„DataFrame“ yra baigtas čia, o dabar turime atspausdinti šį „DataFrame“, todėl čia įdedame „spausdinti ()“. Norime gauti konkrečių duomenų iš šio „DataFrame“, todėl čia nustatome tam tikras sąlygas. Čia pateikiamos dvi sąlygos ir tarp šių sąlygų pridedame operatorių „IR“, todėl jis grąžins tik tas sąlygas, kurios tenkins abi sąlygas. Pirmoji sąlyga, kurią čia įtraukėme, yra „balas > 20“, tada įdėkite operatorių „&“ ir kitą sąlygą, kuri yra „Out == 9“.
Taigi, jis išfiltruos tuos duomenis, kuriuose komandos rezultatas yra mažesnis nei 20, o jų išėjimai yra 9. Filtruoja tuos ir ignoruoja likusius, kurie neatitiks nei abiejų sąlygų, nei vienos iš jų. Taip pat rodome tuos duomenis, kurie atitinka abi sąlygas, todėl panaudojome „spausdinimo ()“ metodą.
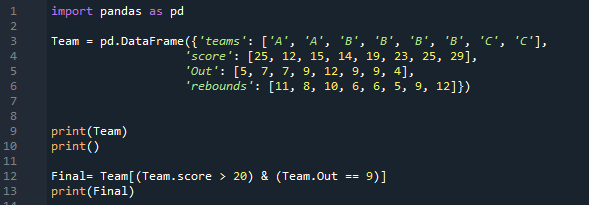
Tik dvi eilutės atitinka abi sąlygas, kurias pritaikėme šiam duomenų rėmeliui. Jis filtruoja tik tas eilutes, kuriose rezultatas yra didesnis nei 20, o jų išėjimai yra 9 ir rodomi čia.
03 pavyzdys
Aukščiau pateiktuose koduose tiesiog įterpiame skaitmeninius duomenis į savo „DataFrame“. Dabar į šį kodą įdedame kai kuriuos eilučių duomenis. Importavę „pandas kaip pd“, pereiname prie duomenų rėmelio „Member“ kūrimo. Jame yra keturi unikalūs stulpeliai. Pirmojo stulpelio pavadinimas čia yra „Vardas“ ir įterpiame narių vardus, ty „Allies, Bills, Charles, David, Ethen, George ir Henry“. Kitas stulpelis čia pavadintas „Vieta“, o jame yra „Amerika. Kanada, Europa, Kanada, Vokietija, Dubajus ir Kanada“. Stulpelyje „Kodas“ yra „W, W, W, E, E, E ir E“. Čia taip pat pridedame narių „taškus“ kaip „11, 6, 10, 8, 6, 5 ir 12“. „Nario“ duomenų rėmelį pateikiame naudodami „spausdinimo ()“ metodą. Šiame duomenų rėmelyje nurodėme kai kurias sąlygas.
Čia turime dvi sąlygas ir tarp jų pridėjus operatorių „IR“, bus grąžintos tik abi sąlygas tenkinančios sąlygos. Čia pirmoji sąlyga, kurią pristatėme, yra „Location == Canada“, po kurios seka „&“ operatorius, o antroji sąlyga – „taškai <= 9“. Jis gauna tuos duomenis iš „DataFrame“, kai tenkinamos abi sąlygos, ir tada įdėjome „spausdinti ()“, kuriame rodomi tie duomenys, kuriuose abi sąlygos yra teisingos.
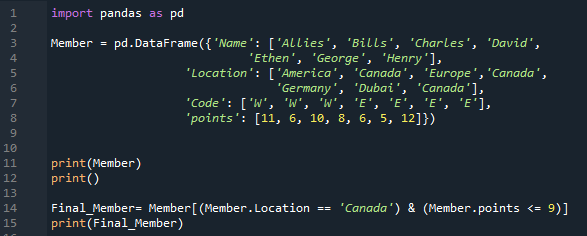
Žemiau galite pastebėti, kad iš „DataFrame“ ištraukiamos ir rodomos dvi eilutės. Abiejose eilutėse vieta yra „Kanada“, o taškai yra mažesni nei 9.
04 pavyzdys
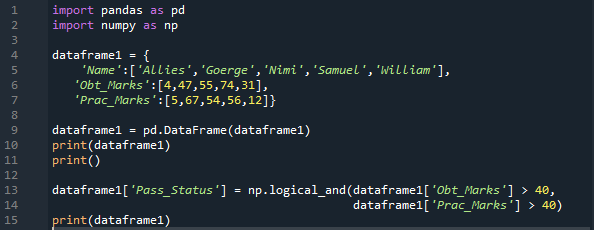
Čia importuojame ir „pandas“, ir „numpy“ atitinkamai kaip „pd“ ir „np“. „Pandos“ metodus gauname įdėję „pd“, o „numpy“ metodus – „np“ kur reikia. Tada mūsų sukurtame žodyne yra trys stulpeliai. Stulpelyje „Vardas“, kuriame įterpiame „Sąjungininkai, George'as, Nimi, Samuelis ir Williamas“. Toliau turime stulpelį „Obt_Marks“, kuriame yra surinkti mokinių pažymiai, o tie pažymiai yra „4, 47, 55, 74 ir 31“.
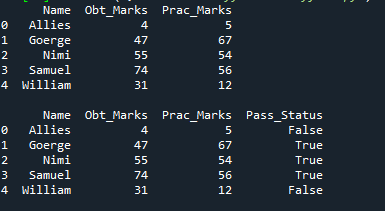
Čia taip pat sukuriame stulpelį „Prac_Marks“, kuriame yra praktiniai mokinio pažymiai. Čia pridedami ženklai yra „5, 67, 54, 56 ir 12“. Sukuriame šio žodyno duomenų rėmelį ir atspausdiname. Čia taikome „np.Logical_and“, kuri pateiks rezultatą „Tiesa“ arba „Klaidinga“ forma. Taip pat išsaugome rezultatą patikrinę abi sąlygas naujame stulpelyje, kurį čia sukūrėme pavadinimu „Pass_Status“.
Jis patikrina, ar „Obt_Marks“ yra didesnis nei „40“, o „Prac_Marks“ yra didesnis nei „40“. Jei abu yra teisingi, tai naujame stulpelyje bus pateikta tiesa; kitu atveju jis paverčia klaidingu.
Naujas stulpelis pridedamas pavadinimu „Pass_Status“, o šį stulpelį sudaro tik „True“ ir „False“. Tai yra tiesa, kai gauti balai ir praktiniai balai yra didesni nei 40, o likusiose eilutėse – false.
Išvada
Pagrindinis šios pamokos tikslas yra paaiškinti „pandų“ sąvoką „ir sąlyga“. Kalbėjome apie tai, kaip gauti tas eilutes, kuriose tenkinamos abi sąlygos, arba gauname teisingą toms, kuriose tenkinamos visos sąlygos, ir klaidingas likusioms. Čia išnagrinėjome keturis pavyzdžius. Visi keturi pavyzdžiai, kuriuos sukūrėme šioje mokymo programoje, buvo atlikti per šį procesą. Visi šios pamokos pavyzdžiai buvo apgalvotai pateikti jūsų naudai. Ši pamoka turėtų padėti jums aiškiau suprasti šią idėją.