„Kableliais atskirtos reikšmės (CSV) yra vienas universaliausių ir lengviausiai naudojamų duomenų formatų. Tai lengvas duomenų formatas, leidžiantis kūrėjams ir programoms perkelti ir analizuoti duomenis iš vieno šaltinio į kitą.
CSV duomenys saugo duomenis lentelės formatu, kur kiekvienas stulpelis atskiriamas kableliu, o naujas įrašas priskiriamas naujai eilutei. Dėl to tai labai geras pasirinkimas eksportuojant duomenų bazes, tokias kaip SQL duomenų bazės, Cassandra duomenys ir kt.
Todėl nenuostabu, kad susidursite su scenarijumi, kai turėsite importuoti CSV failą į savo duomenų bazę.
Šios pamokos tikslas yra parodyti jums greitą ir paprastą būdą, kaip importuoti CSV failą į savo Elasticsearch klasterį naudojant Kibana prietaisų skydelį.
Įšokime.
Reikalavimai
Prieš nardydami įsitikinkite, kad atitinkate šiuos reikalavimus:
- „Elasticsearch“ klasteris, turintis žalią sveikatos būklę.
- Kibana serveris prijungtas prie jūsų Elasticsearch klasterio.
- Pakankami leidimai tvarkyti indeksus jūsų grupėje.
CSV failo pavyzdys
Kaip įprasta, pirmasis reikalavimas yra šaltinio CSV failas. Verta užtikrinti, kad jūsų CSV failo duomenys būtų tinkamai suformatuoti ir jame nėra klaidų.
Iliustracijos tikslais naudosime nemokamą duomenų rinkinį, kuriame yra filmų ir TV laidų iš „Amazon Prime“.
Atidarykite naršyklę ir eikite į toliau pateiktą šaltinį:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Vykdykite procedūrą, kad atsisiųstumėte duomenų rinkinį į vietinį įrenginį. Atsisiųstą archyvą galite ištraukti naudodami komandą:
$ išpakuokite a~ / Atsisiuntimai / archyvas.zip
Importuoti CSV failą
Kai turėsite šaltinio failą, galėsime tęsti ir aptarti, kaip jį importuoti.
Pradėkite eidami į „Kibana“ namų prietaisų skydelį ir pasirinkdami parinktį „įkelti failą“.
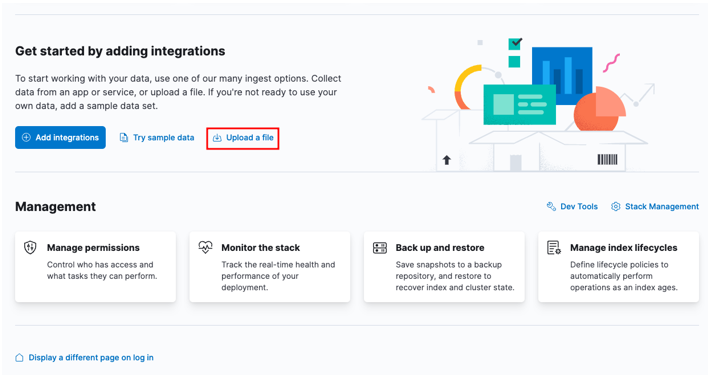
Paleidimo priemonės lange suraskite tikslinį CSV failą, kurį norite importuoti.
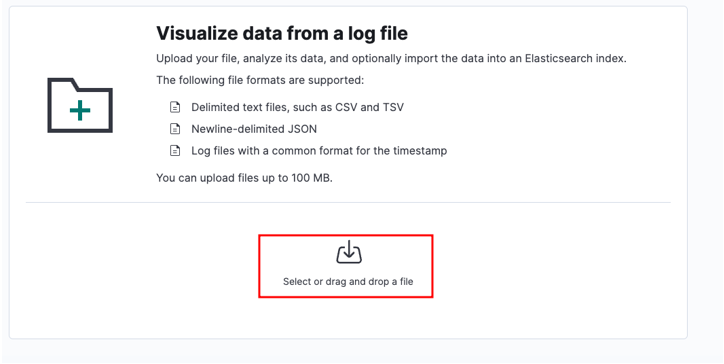
Pasirinkite šaltinio failą ir spustelėkite įkelti.
Leiskite Elasticsearch ir Kibana analizuoti įkeltą failą. Tai išnagrinės CSV failą ir nustatys duomenų formatą, laukus, duomenų tipus ir kt.
PASTABA: atsižvelgiant į jūsų grupės konfigūraciją ir duomenų dydį, šis procesas gali užtrukti. Įsitikinkite, kad pagrindinis mazgas reaguoja, kad išvengtumėte skirtojo laiko.
Kai procesas bus baigtas, turėtumėte gauti failo turinio pavyzdį ir failo statistiką, kurią išanalizavo Elastic.
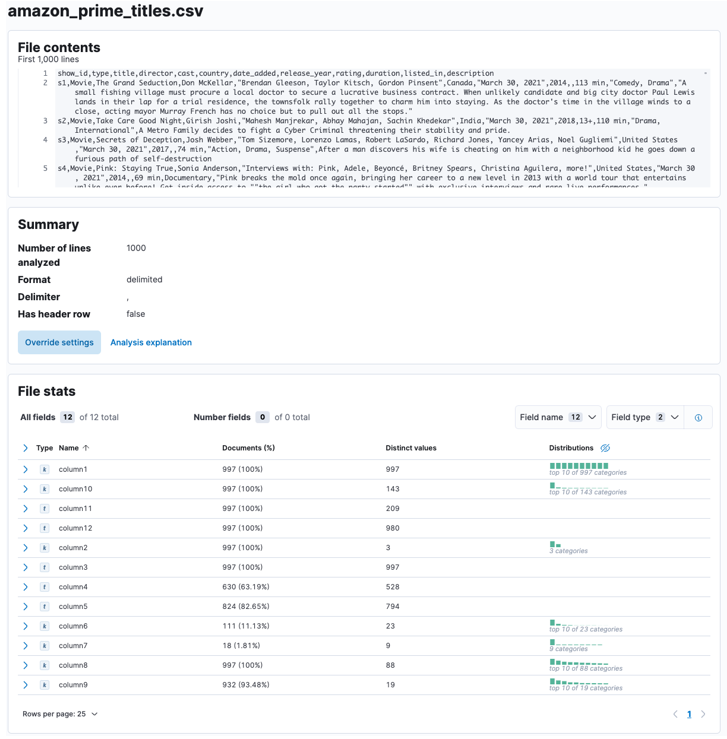
Galite pritaikyti daugybę parametrų, pavyzdžiui, skyriklį, antraštės eilutes ir kt. Pavyzdžiui, galime tinkinti aukščiau pateiktą išvestį, kad praneštume Elastic, kad mūsų CSV faile yra antraščių failų.
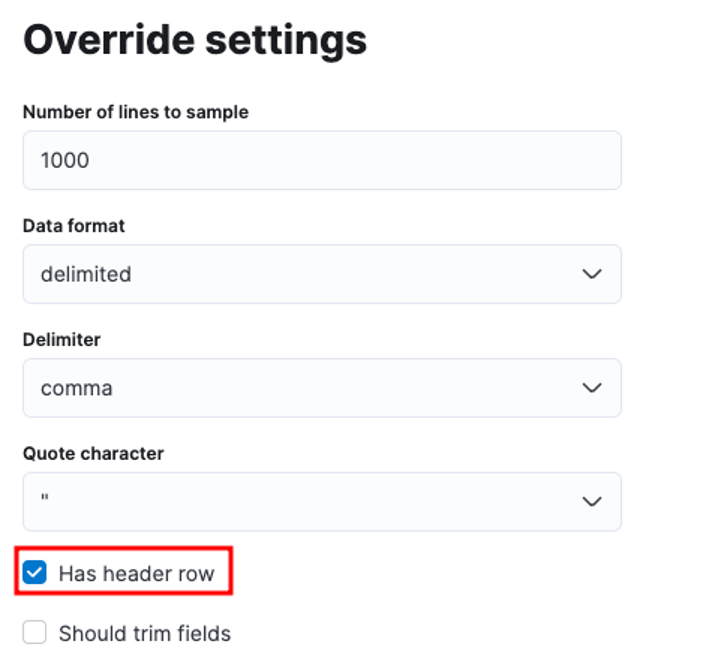
Tada galime spustelėti taikyti ir iš naujo analizuoti duomenis. Tai turėtų suformatuoti duomenis teisingu formatu, įskaitant laukus.
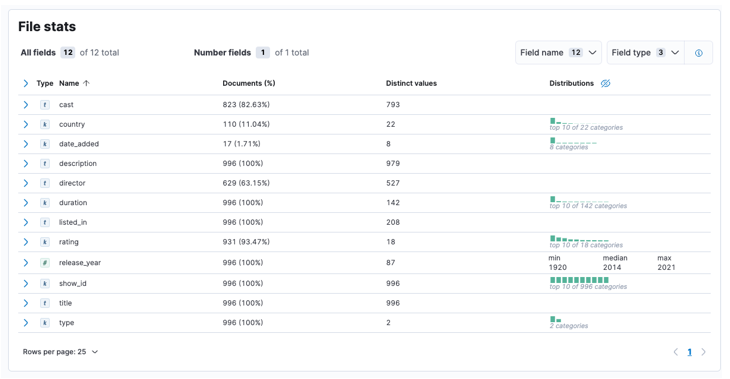
Tada galime spustelėti importuoti, kad pereitumėte į importuotą prietaisų skydelį.
Čia turime sukurti indeksą, kuriame būtų saugomi CSV duomenys. Savo indeksui galite priskirti bet kokį palaikomą pavadinimą.
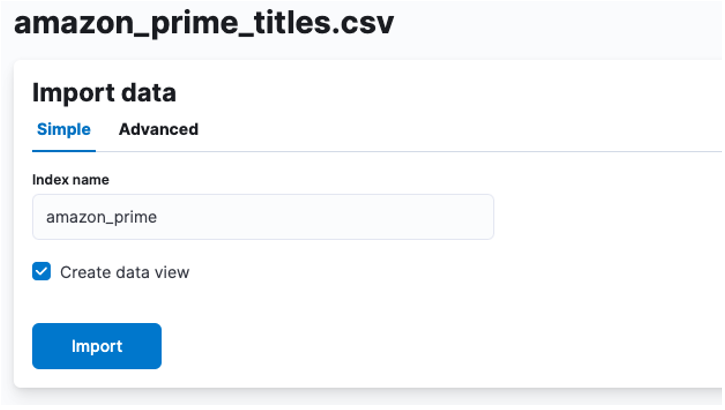
Jei norite tinkinti savo rodyklės ypatybes, pvz., šukių, kopijų, atvaizdų skaičių ir t. t. Pasirinkite išplėstinę parinktį ir pakoreguokite nustatymus, kaip geidžia.
Galiausiai spustelėkite importuoti ir stebėkite, kaip „Kibana“ atlieka savo „stebuklingumą“. Baigę galite pasiekti savo indeksą naudodami „Elasticsearch“ API arba naudodami „Kibana“ prietaisų skydelį.
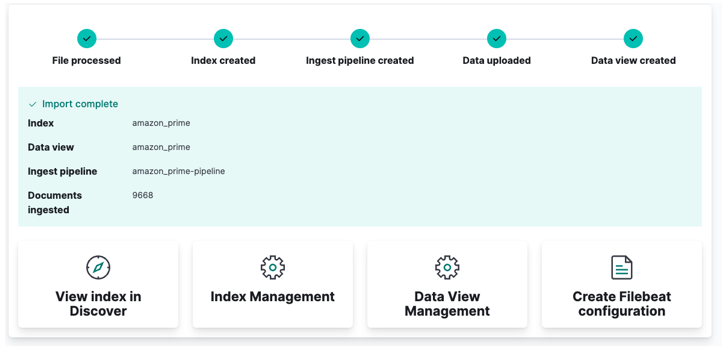
Ir baigei!!
Išvada
Šiame įraše apžvelgėme CSV duomenų rinkinio gavimo ir importavimo į „Elasticsearch“ grupę naudojant „Kibana“ prietaisų skydelį.
Ačiū, kad skaitėte ir laimingo kodavimo!!