Kilis (Knowledge Extraction, pagrįstas evoliuciniu mokymusi) yra Java pagrindu sukurtas programinės įrangos įrankis, kurio specializacija yra evoliucinių algoritmų įgyvendinimas. Kadangi tai yra atvirojo kodo, jame yra daug įvairių žinių atskleidimo algoritmų, kuriuos galima naudoti eksperimentuose, kurie suteikia energijos duomenų gavybos ir analizės bendruomenei. Tai suteikia paprastą ir lengvai naudojamą grafinę vartotojo sąsają, kuri žymiai sumažina bendrą šio įrankio sudėtingumą. Dauguma panašių rinkoje esančių įrankių reikalauja, kad vartotojai sąveikautų su jais rašydami kodą, o „Keel“ pašalina šį reikalavimą pateikdamas intuityvią GUI, kurią gali naudoti ir pradedantieji, ir ekspertai.
„Keel“ siūlo daugybę skirtingų skaičiavimo intelektu pagrįstų algoritmų, įskaitant klasifikavimą, regresiją, funkcijų išskyrimą, modelių analizę, grupavimą ir kt. Įprasti modeliai įdedami tiesiai į pačią programą, todėl „Keel“ yra labai naudinga priemonė, kai reikia atlikti žvalgomąją neapdorotų duomenų rinkinių duomenų analizę. Jo paprasta nuvilkimo sąsaja, susieta su funkcionalumo paprastumu, leidžia greitai ir efektyviai eksperimentuoti su duomenų gavyba tiek švietimo, tiek tyrimų tikslais. Tokie įrankiai kaip „Keel“ populiarėja dėl supaprastinto požiūrio į kitaip sudėtingas algoritmines praktikas.
Montavimas
Yra du pagrindiniai diegimo būdai Kilis bet kuriame Linux kompiuteryje. Pirmasis apima ėjimą į Keel tinklalapis ir atsisiųskite programinę įrangą iš ten. Antrasis, kurio vadovausimės šiame diegimo vadove, reikalauja, kad „Keel“ atsisiųstume naudodami wget „Linux“ naudotojams prieinamas atsisiuntimo įrankis.
1. Pradedame nuo to, kad gauname wget mūsų Linux kompiuteryje.
Vykdykite šią komandą, kad atsisiųstumėte wget naudodami apt paketo tvarkyklė:
$ sudo apt-get install wget
Pamatysite panašų terminalo išvestį:
2. Dabar, kai turime wget įrankį, įdiegtą mūsų „Linux“ įrenginyje, naudojame jį atsisiųsti Kilis įrankis.
Tai yra nuoroda kad pereiname į wget.
Savo terminale paleiskite šią komandą:
$ wget http: // sci2s.ugr.es / kilis / programinė įranga / prototipai / openVersion / programinė įranga- 2018 m -04-09.zip
Savo terminale turėtumėte matyti panašią išvestį:
Kai „Keel“ baigs atsisiuntimą, galime tęsti likusią diegimo dalį.
3. Dabar išgauname suspaustą failą, kurį atsisiuntėme atlikdami ankstesnį veiksmą naudodami Linux Unzip įrankį.
Vykdykite šią komandą:
$ išpakuokite programinė įranga- 2018 m -04-09.zip
Panašią išvestį turėtumėte pamatyti terminale:
4. Eikite į aplanką „Keel“ vykdydami šią komandą:
$ cd programinė įranga- 2018 m -04-09 / dokumentus / eksperimentai / KEEL / raj /
5. Norėdami pradėti diegti, paleiskite šią komandą:
$ java - stiklainis . / GraphInterKeel.jar
Tokiu būdu „Keel“ turėtų būti prieinama naudoti „Linux“ įrenginyje.
Naudotojo gidas
Bendraujant su Kilis taikymas yra tikrai lengvas ir paprastas. Pradėkime nuo importavimo Iris duomenų rinkinys į mūsų darbo vietą.
Kai importuojame duomenis, įrankis mums parodo bendrą duomenų taško grupavimą duomenų rinkinyje. Jame taip pat rodomos skirtingos duomenų rinkinyje esančios klasės kartu su pagrindine informacija, pvz., skaitiniais diapazonais, kuriuos apima šie duomenų taškai, ir bendrą dispersiją bei vidutines reikšmes. Ši informacija leidžia vartotojams geriau suprasti, kaip toliau ruošti duomenis bet kokiai duomenų analizės užduočiai.
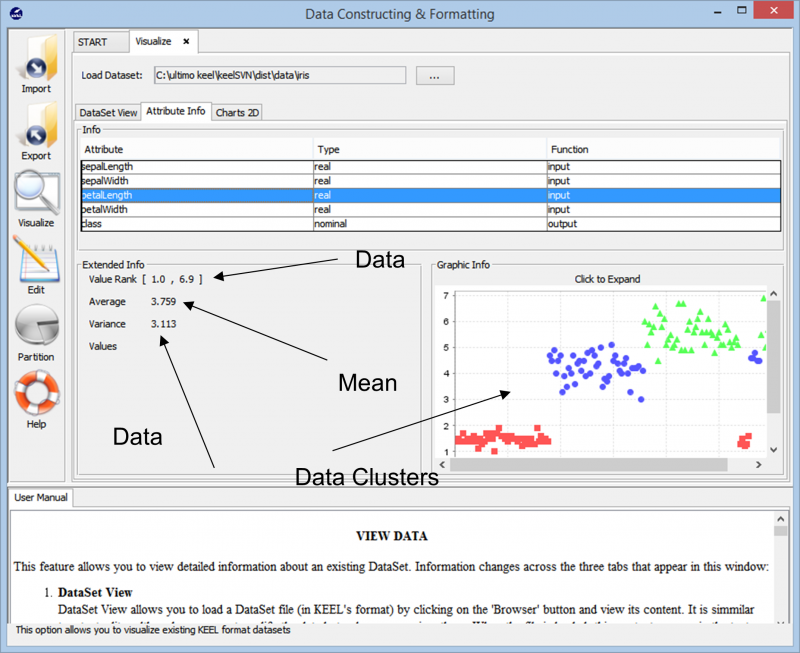
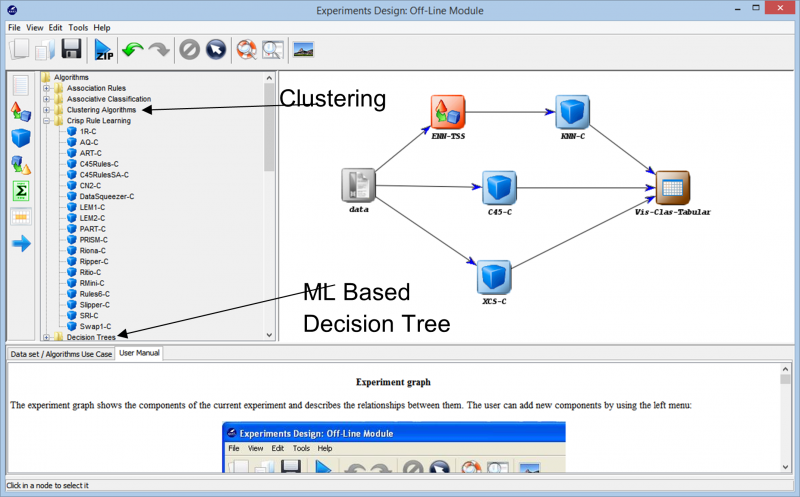
Tęsdami eksperimentą, susiduriame su įvairiais metodais, kuriuos galima naudoti kuriant eksperimentą su bet kokiu duomenų rinkiniu. Įvairūs mokymosi algoritmai, kurie gali būti naudojami mūsų duomenims, gali būti matomi kitame paveikslėlyje. Priklausomai nuo duomenų rinkinio pobūdžio ir eksperimento reikalavimų, galima eksperimentuoti su skirtingais algoritmais.
Pavyzdžiui, jei dirbate su nepažymėtais duomenimis ir turite rasti panašumų tarp skirtingų duomenų rinkinio duomenų taškų, grupavimo algoritmas iš įvairių galimų parinkčių gali padėti geriau suprasti duomenų taškus. Tai galiausiai padeda pažymėti ir klasifikuoti duomenų taškus, kad eksperimentą būtų galima sukurti naudojant išsamesnius prižiūrimus mokymosi algoritmus.
Išvada
The Kilis duomenų analizės platforma yra geras šaltinis tiek mokslinių tyrimų, tiek švietimo tikslais. Tai lengvai naudojama grafinė vartotojo sąsaja, padedanti vartotojams geriau suprasti duomenų reikalavimus, taip pat pateikti loginių nuorodų į naudingus metodus ir algoritmus, kurie dar labiau padeda vartotojams jų darbo eigoje. Turėdami daugybę skirtingų algoritmų, kurie patenka į skirtingas kategorijas ir algoritminius metodus, vartotojai gali eksperimentuoti su daugybe loginių krypčių ir palyginti šiuos rezultatus, kad būtų galima pasiekti optimaliausią bet kokios problemos sprendimą.
„Keel“ be kodo taikomas duomenų gavybos „drag and drop“ metodas padeda net pradedantiesiems be vargo dirbti su išsamiais skaičiavimo žvalgybos modeliais. Tai suteikia įžvalgų apie sudėtingus duomenų rinkinius ir daromos naudingos išvados, padedančios išspręsti realaus pasaulio problemas.